 こんにちは。株式会社HelpfeelでScrapboxの開発をしているid:balarです。
こんにちは。株式会社HelpfeelでScrapboxの開発をしているid:balarです。
この記事はHelpfeel Advent Calendar 2022の17日目の記事です。
昨日は@h.ozakiさんによる「奥が深い、Helpfeelのインサイドセールス」のお話でした。
corp.helpfeel.com
今日はScrapboxのファイル検索の仕組みと、実装にあたって工夫した事をお話しします。
Scrapboxのファイル検索
Scrapboxにはファイルをアップロードする機能があります。この処理にはGoogle Cloud Strageを利用しています。
実は、このアップロードしたファイルの中身を検索する事が可能です。現在は以下のファイルの形式に対応しています。
- テキストファイル
- 画像ファイルのOCR
- PDFファイルのファイル名やテキスト
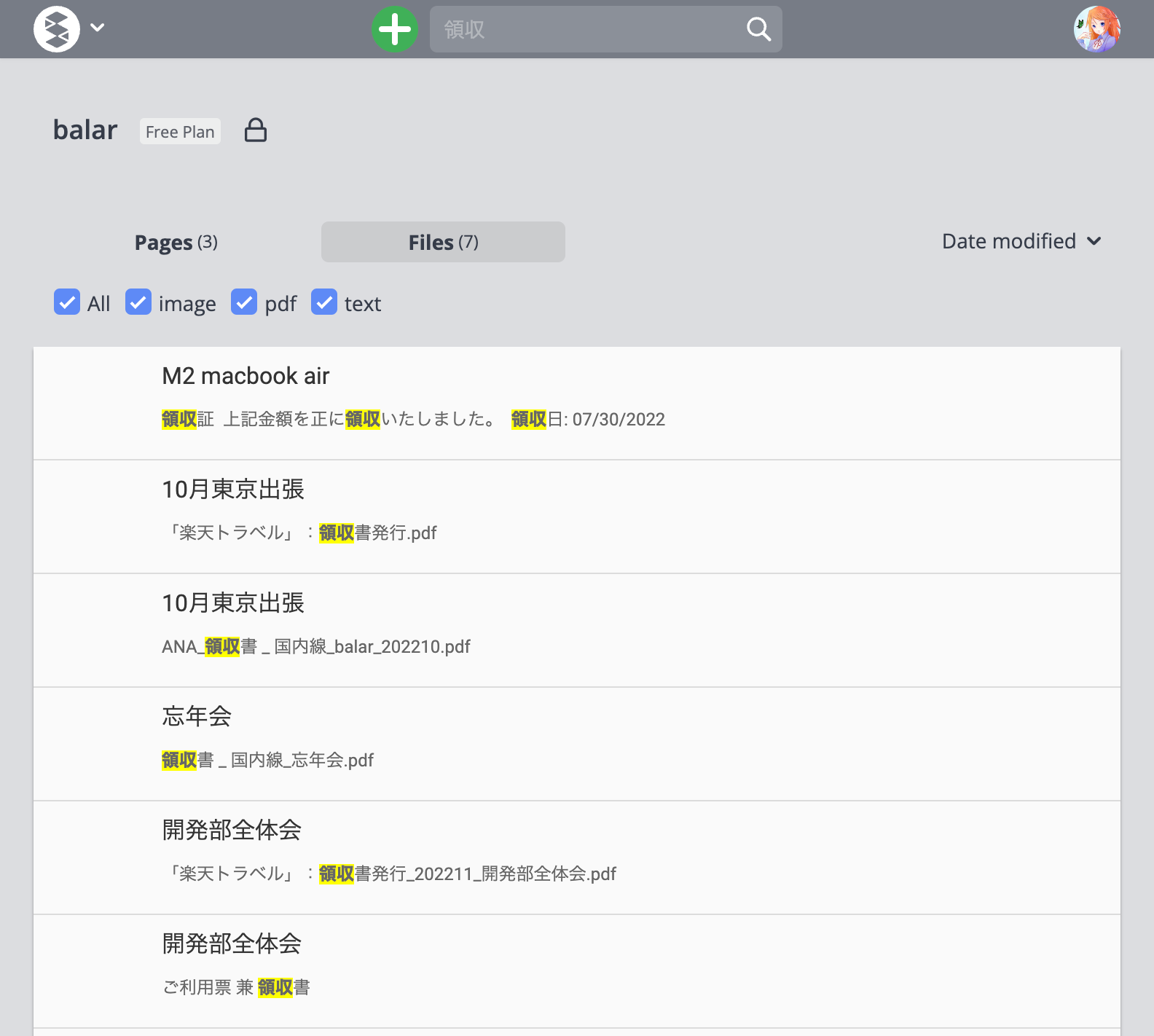
Scrapboxで検索をした時、ファイルの検索結果は「Files」のタブをクリックすると表示されます。
 gyazo.com
この画像は、私用Scrapboxに経費申請用の領収書のスクショやPDFを貼り付け、「領収」というワードで検索をした結果を写したものです。スクショ内の「領収」の文字や、PDFファイル名の「領収」がヒットしており、検索ができている事がわかります。
gyazo.com
この画像は、私用Scrapboxに経費申請用の領収書のスクショやPDFを貼り付け、「領収」というワードで検索をした結果を写したものです。スクショ内の「領収」の文字や、PDFファイル名の「領収」がヒットしており、検索ができている事がわかります。
また、上部にあるチェックボックスでON/OFFを切り替える事で、検索するファイルを絞り込む事が可能です。
ファイル検索の仕組み
ファイル検索は、ファイル内のテキストを取得する処理と、検索する処理に分かれています。取得部分にはGoogle Cloud Functions、検索部分にはElasticsearchを利用しています。ElasticsearchのサーバーはElastic Cloudにホスティングしてもらっています。
ファイルのアップロード完了をトリガーにして呼び出されたCloud Functionsが、ファイルに対して下記の処理を実行します。そうして取得したテキストを、Scrapboxのデータを保存しているMongoDBと、検索処理に利用しているElastic Cloudに登録します。
Cloud Functionsが実行する処理
ファイルのContent-Typeによって、実行する処理をテキスト/画像/PDFに分岐
ファイル検索の実装にあたって工夫した事
開発中に発生したエラーを、その原因と解決策もあわせていくつか紹介します。
エラー①:長文テキストファイルのアップロードに失敗する
長文のテキストファイルをアップロードしようとすると、エラーが発生しました。
原因はCloud Functionsのレスポンスサイズに上限がある事でした。
割り当て | Google Cloud Functions に関するドキュメント
リンク先の「リソースに関する上限」に「非圧縮 HTTP レスポンスの最大サイズ|HTTP レスポンスで HTTP 関数から送信されるデータ|10 MB」と記載があるとおり、ファイルアップロードの上限サイズが10MBよりも大きいために起こる現象でした。
解決策は「長文の場合は上限を超えないよう、先頭からテキストを切り取る」です。
エラー②:パスワード付きPDFファイルが読めない
PDFファイルにはパスワードが設定されている事があります。パスワードが設定されたPDFファイルの中身を読もうとすると、エラーが発生しました。
解決策は「パスワード付きPDFファイルは読むのをskipする」です。
エラー③:壊れたPDFファイルが読めない
PDFファイルはbuildに失敗したりして壊れている事があります。壊れたPDFファイルの中身を読もうとすると、エラーが発生しました。
解決策は「壊れたPDFファイルは、パスワード付きPDFファイルと同じく、読むのをskipする」です。
エラー④:巨大なPDFファイルが読めない
巨大なPDFファイルを読もうとすると、メモリリークのエラーが発生しました。
原因はmax_old_space_sizeを指定していない事でした。
Migrating Cloud Functions to newer Node.js runtimes | Cloud Functions Documentation | Google Cloud
リンク先に「Node.js 12 以降の場合、メモリの上限が 2 GiB を超える関数では、max_old_space_size を持つように NODE_OPTIONS を構成する必要があります。」と記載があります。Cloud Functionsには2GBを指定していましたが、このオプションは指定していませんでした。
解決策は「デプロイ時に--set-env-vars NODE_OPTIONS="--max_old_space_size=2048"を指定する」です。これで巨大なPDFファイルを読む場合でもメモリリークが起きる事なく、テキストを取得できるようになりました。
Scrapboxには当初、画像のOCRを検索する機能だけが実装されていました。リリース後、開発者である自分たちがユーザーとしてScrapboxに触れる中で、他のファイル形式やファイル名を検索する機能、ファイル形式で絞り込む機能の必要性に気づき、その開発に着手したという経緯があります。いわゆるドッグフーディングをきっかけにした、「体験」に基づく機能であるからこそ、ユーザーのニーズの芯をとらえる事ができるはずだ!と信じています。ぜひ、たくさんの方にファイル検索を知っていただき、お手元で試してみていただきたいです。
なお、新しい機能を追加する時には、Elasticsearchの設計も変更する必要があります。Scrapbox開発においては、設計変更を気軽に実行できる運用上の仕組みが採用されています。そのおかげで、改善活動そのものに過大なリソースが割かれてしまうような事はありません。
その仕組みについて、詳しくはHelpfeel Advent Calendar 2022 12日目の記事で解説されています。
まとめ
ファイル検索は「実装→エラー→解決→またエラー…」という試行錯誤のサイクルを繰り返す事で洗練されてきました。もちろん、サイクルはこれからも続きます。ドッグフーディングと、開発の運用上の仕組みのかけ合わせによって、そのサイクルを短くできるところがScrapbox開発の良いところだと思っています。今回お話ししたファイル検索の他にも、通常のページ検索やモバイル向け操作など、Scrapboxは日々改良されています。これからも楽しみにしていてください!
株式会社Helpfeelでは、ドッグフーディングや試行錯誤が好きな人を募集しています。